Basic Workflow
Walk you through the suggested basic workflow for using Codee, demonstrated with a C project.
Getting ready
For this demonstration, we will use a C implementation of a matrix multiplication. Start by cloning the repository:
git clone https://github.com/codee-com/codee-demos.git
Walkthrough of the workflow
Our suggested basic workflow begins with management-oriented reports before diving into more detailed, developer-focused insights. This top-down approach helps ensure that strategic goals are aligned with technical actions during project development.
Follow along each step of the basic workflow and refer to the accompanying diagram to see how each part of the process interconnects.
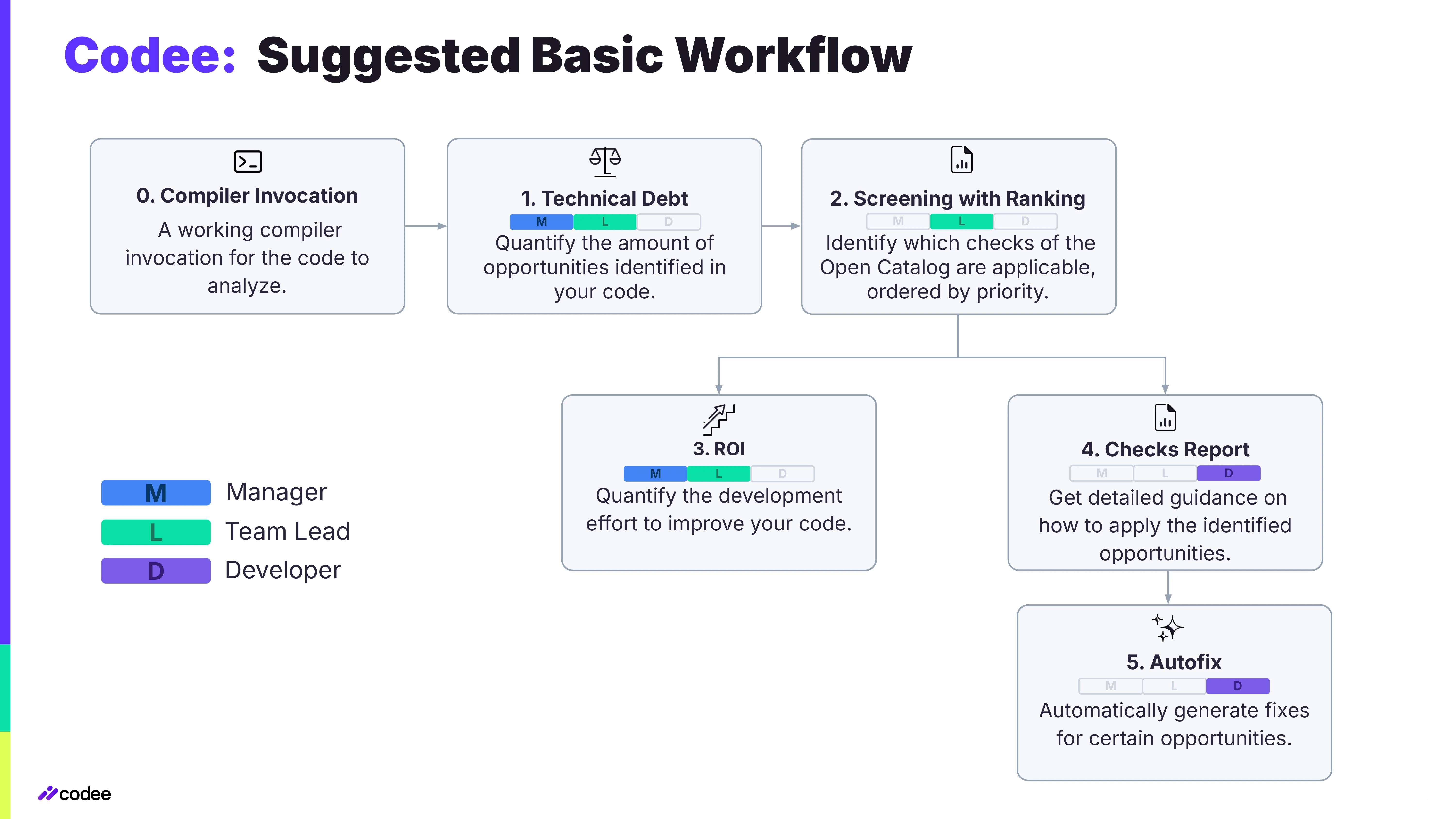
0. Compiler Invocation
Firstly navigate to the source code directory:
- Linux
- Windows
cd codee-demos/C/MATMUL
cd codee-demos\C\MATMUL
Before using Codee, ensure you have a working compiler invocation for the
code to analyze. We will focus on the main.c file, which contains the core
computational code. The file can be compiled as:
gcc main.c -c -I include/ -O3
To generate any Codee report, simply add the compiler invocation to the
right of the codee invocation after a -- separator.
1. Technical Debt
This report quantifies as a single number, the technical debt score, all code refactors that are necessary to leverage all improvement opportunities identified by Codee. Over time, your goal should be to progressively reduce this score to zero:
codee technical-debt -- gcc main.c -c -I include/ -O3
TECHNICAL DEBT REPORT
This report quantifies the technical debt associated with the modernization of legacy code by assessing the extent of refactoring required for language constructs. The score is determined based on the number of language constructs necessitating refactoring to bring the source code up to modern standards. Additionally, the metric identifies the impacted source code segments, detailing affected files, functions, and loops.
Score Affected files Affected functions Affected loops
----- -------------- ------------------ --------------
6 1 1 4
TECHNICAL DEBT BREAKDOWN
Lines of code Analysis time Checkers Technical debt score
------------- ------------- -------- --------------------
55 14 ms 6 6
SUGGESTIONS
Use 'checks' to find out details about the detected checks:
codee checks -- gcc main.c -I include/ -O3
1 file, 2 functions, 6 loops successfully analyzed and 0 non-analyzed files in 14 ms
2. Screening with Ranking
While the technical debt report provides guidance on how many issues there are, the screening report details which recommendations of the Open Catalog are applicable to the code, and ranks them based on their estimated positive impact to help prioritize the refactoring efforts:
codee screening -- gcc main.c -c -I include/ -O3
SCREENING REPORT
---Number of files---
Total | C C++ Fortran
----- | - --- -------
1 | 1 0 0
RANKING OF QUALITY CHECKERS
Checker Category Priority AutoFixes # Title
------- -------- -------- --------- - -----
Total 0
RANKING OF OPTIMIZATION CHECKERS
Checker Category Priority AutoFixes # Title
------- -------- -------- --------- - ----------------------------------------------------------------------------------------------------------------------
PWR039 memory P27 (L1) 1 1 Consider loop interchange to improve the locality of reference and enable vectorization
PWR053 vector P12 (L1) 1 1 Consider applying vectorization to forall loop
PWR010 memory P4 (L3) 1 Avoid column-major array access in C/C++
PWR048 scalar P3 (L3) 1 Replace multiplication/addition combo with an explicit call to fused multiply-add
PWR035 memory P2 (L3) 1 Avoid non-consecutive array access to improve performance
RMK010 vector P0 (L4) 1 The vectorization cost model states the loop is not a SIMD opportunity due to strided memory accesses in the loop body
------- -------- -------- --------- - ----------------------------------------------------------------------------------------------------------------------
Total 2 6
SUGGESTIONS
Use 'roi' to get a return of investment estimation report:
codee roi -- gcc main.c -c -I include/ -O3
Use 'checks' to find out details about the detected checks:
codee checks -- gcc main.c -c -I include/ -O3
1 file, 2 functions, 6 loops, 55 LOCs successfully analyzed (6 checkers) and 0 non-analyzed files in 28 ms
3. ROI
Once we have an overview of all the identified improvement opportunities, the ROI report estimates the effort and time savings realized through the automated analysis that Codee has just performed. The estimation compares the time that would have been needed to manually evaluate each part of the code analyzed against every rule in the Open Catalog to identify the improvement opportunities:
codee roi -- gcc main.c -c -I include/ -O3
ROI ANALYSIS SUMMARY
This analysis underscores the tangible benefits Codee brings to the development process, not only in terms of savings in development effort, but also in realizing significant cost efficiencies for the organization.
Impact on Development Effort:
This report identifies critical areas within the source code that necessitate attention from the development team, and forecasts a significant reduction in workload by an estimated 290 hours.
Without Codee | With Codee | Hours saved
------------- | ---------- | -----------
296 hours | 6 hours | 290 hours
Impact on Cost Savings:
Considering a standard developer's workload of approximately 1800 hours/year, Codee's intervention translates to saving an equivalent to 0.16 (290h / 1800h) developers working full-time. Assuming an average cost of a developer for the company (salary + associated costs) of €100,000, this amounts to cost savings of €16,111 (€100,000 x 0.16).
Developer hours/year | Number of devs. saved/year | Developer salary/year | Total costs saved/year
-------------------- | -------------------------- | --------------------- | ----------------------
1800 hours | 0.16 | €100,000 | €16,111
SUGGESTIONS
Set custom parameters for the ROI calculation, using --dev-cost-per-year, --dev-hours-per-year, and --checker-effort flags; e.g.:
codee roi --dev-cost-per-year 20000 --dev-hours-per-year 1600 --checker-effort 1.5 -- gcc main.c -c -I include/ -O3
Use --check-id <list of checkers separated by comma> to calculate the ROI for an arbitrary subset of checkers to enable; e.g.:
codee roi --check-id PWR030,PWR039 -- gcc main.c -c -I include/ -O3
1 file, 2 functions, 6 loops, 55 LOCs successfully analyzed (6 checkers) and 0 non-analyzed files in 31 ms
4. Checks Report
To apply the recommendations from the Open Catalog, the checks report identifies the precise locations in the source code where the improvement opportunities have been found. The default checks report pinpoints the file, line, and column for each opportunity:
codee checks -- gcc main.c -c -I include/ -O3
CHECKS REPORT
main.c:16:9 [PWR039] (level: L1): Consider loop interchange to improve the locality of reference and enable vectorization
main.c:9:9 [PWR053] (level: L1): Consider applying vectorization to forall loop
main.c:17:13 [PWR010] (level: L3): Avoid column-major array access in C/C++
main.c:18:17 [PWR048] (level: L3): Replace multiplication/addition combo with an explicit call to fused multiply-add
main.c:15:5 [PWR035] (level: L3): Avoid non-consecutive array access to improve performance
main.c:17:13 [RMK010] (level: L3): The vectorization cost model states the loop is not a SIMD opportunity due to strided memory accesses in the loop body
SUGGESTIONS
Use --verbose to get more details, e.g:
codee checks --verbose -- gcc main.c -c -I include/ -O3
Use --check-id to focus on specific subsets of checkers, e.g.:
codee checks --check-id PWR039 -- gcc main.c -c -I include/ -O3
1 file, 2 functions, 6 loops, 55 LOCs successfully analyzed (6 checkers) and 0 non-analyzed files in 29 ms
Typically, you will also use the verbose mode of the checks report to generate detailed information on how to address each improvement opportunity:
codee checks --verbose -- gcc main.c -c -I include/ -O3
CHECKS REPORT
main.c:16:9 [PWR039] (level: L1): Consider loop interchange to improve the locality of reference and enable vectorization
Loops to interchange:
16: for (size_t j = 0; j < n; j++) {
17: for (size_t k = 0; k < p; k++) {
Suggestion: Interchange inner and outer loops in the loop nest to improve performance
Documentation: https://github.com/codee-com/open-catalog/tree/main/Checks/PWR039
AutoFix:
codee rewrite --memory loop-interchange --in-place main.c:16:9 -- gcc main.c -c -I include/ -O3
main.c:9:9 [PWR053] (level: L1): Consider applying vectorization to forall loop
Suggestion: Use 'rewrite' to automatically optimize the code
Documentation: https://github.com/codee-com/open-catalog/tree/main/Checks/PWR053
AutoFix (choose one option):
* Using OpenMP pragmas (recommended):
codee rewrite --vector omp --in-place main.c:9:9 -- gcc main.c -c -I include/ -O3
* Using Clang compiler pragmas:
codee rewrite --vector clang --in-place main.c:9:9 -- gcc main.c -c -I include/ -O3
* Using GCC pragmas:
codee rewrite --vector gcc --in-place main.c:9:9 -- gcc main.c -c -I include/ -O3
* Using ICC pragmas:
codee rewrite --vector icc --in-place main.c:9:9 -- gcc main.c -c -I include/ -O3
* Using combined pragmas, for example (for GCC and Clang pragmas):
codee rewrite --vector gcc,clang --in-place main.c:9:9 -- gcc main.c -c -I include/ -O3
<...>
5. Autofix
In certain scenarios, Codee can automatically apply the suggested improvements to your code. The autofix feature is closely integrated with the verbose output of the checks report, as command-line invocations will be generated for all available autofixes.
For example, let's apply the loop interchange autofix shown earlier. To do
this, copy and paste the suggested command, and replace the --in-place
argument with -o main_codee.c to create a new file with the modification:
codee rewrite --memory loop-interchange -o main_codee.c main.c:16:9 -- gcc main.c -c -I include/ -O3
Results for file '/home/user/codee-demos/C/MATMUL/main.c':
Successfully applied AutoFix to the loop at 'main.c:16:9' [using loop interchange]:
[INFO] Loops interchanged:
- main.c:16:9
- main.c:17:13
Successfully created main_codee.c
Codee automatically marks the rewritten code with comments, allowing you to double-check the changes to ensure correctness:
16,17c16,19
< for (size_t j = 0; j < n; j++) {
< for (size_t k = 0; k < p; k++) {
---
> // Codee: Loop modified by Codee (2024-11-13 11:53:05)
> // Codee: Technique applied: loop interchange
> for (size_t k = 0; k < p; k++) {
> for (size_t j = 0; j < n; j++) {
Finally, let's compile both the original and the optimized code to assess the speed optimization:
-
Original code:
Compilationgcc main.c matrix.c clock.c -o matmul -I include -O3./matmul 1500- Input parameters
n = 1500
- Executing test...
time (s)= 2.146220
size = 1500
chksum = 68432918175 -
Optimized code:
Compilationgcc main_codee.c matrix.c clock.c -o matmul_codee -I include -O3./matmul_codee 1500- Input parameters
n = 1500
- Executing test...
time (s)= 0.641667
size = 1500
chksum = 68432918175
In this case, we have managed to achieve a x3.3 speedup.